
Building a moat for generative AI applications
A guide for startups and investors


It is the billion-dollar question for founders building generative AI startups or venture capitalists looking to invest: Is it possible for startups to build long-term defensibility?
a16z has argued that it is not: “There don’t appear, today, to be any systemic moats in generative AI. As a first-order approximation, applications lack strong product differentiation because they use similar models; models face unclear long-term differentiation because they are trained on similar datasets with similar architectures; cloud providers lack deep technical differentiation because they run the same GPUs; and even the hardware companies manufacture their chips at the same fabs.”
Nevertheless, we set out to identify where moats could develop in the future, with a focus on text-generation applications. Specifically, we searched for places where using generative AI can lead to a technological moat; other possible moats linked to a company’s business model, network effects, etc. are not the focus of this piece.
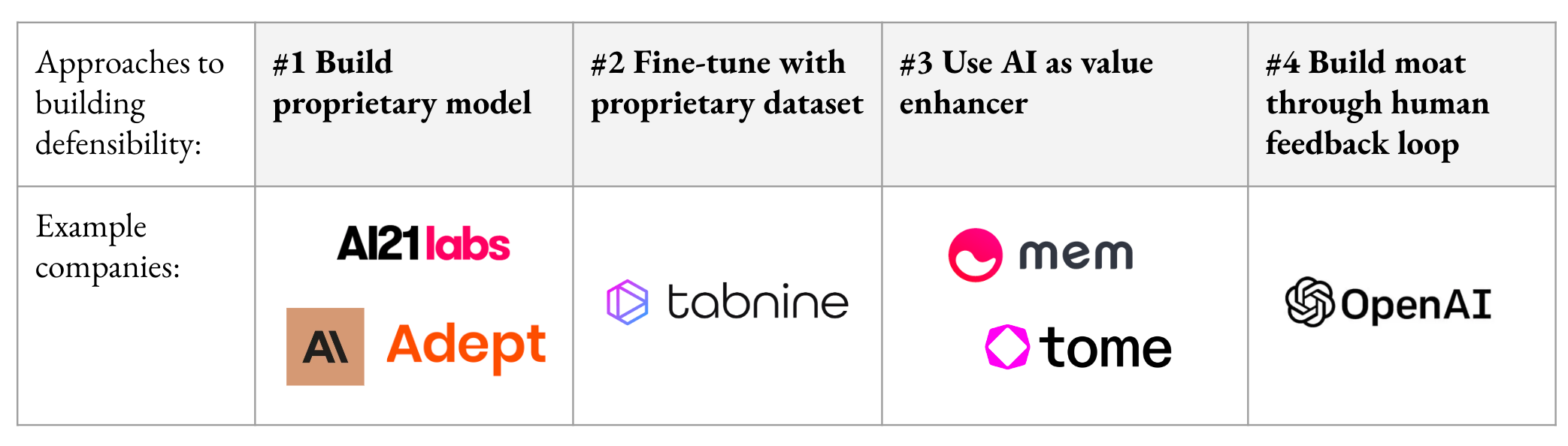
We identified four approaches startups today are taking to build a moat, summarized below and informed by dozens of conversations with founders, engineers and other employees at startups and incumbents building large language models (LLMs), researchers, and VCs. We find that #3 and #4 are the most likely to be a source of an enduring moat for companies. Read on to learn why.
One model to rule them all?
When it comes to defensibility, the biggest question is whether there can be “one model to rule them all.” When OpenAI researchers introduced GPT-3 in a 2020 research paper, they stated: “We presented a 175 billion parameter language model which shows strong performance on many NLP tasks and benchmarks in the zero-shot, one-shot, and few-shot settings, in some cases nearly matching the performance of 40 state-of-the-art fine-tuned systems, as well as generating high-quality samples and strong qualitative performance at tasks defined on-the-fly.”
OpenAI is building massive models, bigger than any of those released by other companies so far. GPT-4, released on March 14, is reported to have one trillion parameters. Google’s biggest model that was released to developers around the same time, PaLM, has 540 billion parameters, and Meta released a paper in February about a model with 65 billion parameters, LLaMa.
OpenAI’s working assumption is that in the long run, a sufficiently large model will be able to outperform smaller models that were trained on niche data sets, even for specialized tasks. This means, for example, that a large model trained on the whole internet would do a better job writing a legal document or writing code than smaller models trained just on legal information or just on code samples. A huge language model could also “teach” a smaller model, or learn how to perform tasks from a very small set of examples, since it could generate synthetic data from those examples to train itself. We believe this is the biggest threat to most startups building applications today, since if one model can truly “rule them all,” a lot of work startups are doing now to power applications in specific verticals may be rendered irrelevant.
To improve the quality of their all-purpose models, companies have largely focused on adding more and more parameters, but recently there is increasing attention to how to “align” the models with human intent, described more below.
Assessing sources of defensibility
We identified four approaches startups are taking to try to build a technological moat for generative AI applications. We describe and assess the merits of each below.
End-to-end applications built on top of proprietary models
How this works: The company builds and trains its own proprietary LLMs, then builds applications on top of them.
Costs: Highly costly. The costs are estimated at tens of millions of dollars to train a proprietary model, even before the first user uses the application. Collecting enough data, obtaining enough compute power, and hiring scarce engineering talent to build and train the model is all very expensive.
What you need to believe: Applications built on top of proprietary architecture and models will lead to superior performance and superior niche capabilities relative to applications that are built on huge models or on fine-tuned third-party models. For example, a model trained mostly on legal data could become a niche expert in IP law and have better results, in the long term, than an agnostic LLM that was not trained specifically for legal tasks.
Risks:
Investors need to believe that:
The founding team will be able to collect the data, build and train the model, and get superior results.
The end product will be superior in a way that is meaningful for the business and customers.
The company will be able to maintain this advantage over a long time.
In a rapidly-changing environment, this will be a hard sell for most teams. The very big LLMs offered by third parties like OpenAI could potentially produce results as good as a “niche” model after fine-tuning on a limited data set.
As new models and new capabilities are being pushed to the market on almost a daily basis, building a proprietary model may slow down a startup and may reduce its flexibility to adopt a better third-party model later on, if one becomes available.
A secondary risk is that the notion of a “better model” may distract us from what is really important. The “outperformed model” is important only to the extent a company can build a better product around it that delivers a better value proposition for the end users and can beat competitors; today, we already see that in performance benchmarks, AI21 Labs’s and Cohere’s models are outperforming some of OpenAI models, but the value is still captured by OpenAI (so we assume). The game is not over—it’s actually only just beginning—but this is a cautionary reminder that the benefit from a better niche model must be translated back to the end-user in a way that the user will recognize.
Conclusion: This potential moat is tightly connected to the future structure of the industry: Will the optimal strategy be for startups to train their own models, or will startups consume LLMs from third-party providers, as they do with cloud computing? We believe this moat is relevant to a tiny fraction of startups. In most cases, unless the team has a unique insight, startups should not be building their own base LLMs, because the models may become outdated quickly, it is very costly, and there is no guarantee that they can eventually produce better results than fine-tuned models.
Applications built on third-party models (open or closed-source), fine-tuned on proprietary data sets
How this works: The company leverages an open-source or closed-source model offered by a third-party as their “base” LLM, then fine-tunes it with a unique, proprietary data set. Several open-source and closed-source models are available today, and new models are published frequently. For example, OpenAI offers the option to fine-tune some, but not all, of its models, which can save a startup the time and money required to the models themselves (davinci-001 can be fine-tuned, while davinci-002 (Codex) can not; OpenAI’s RLHF models are not accessible for fine-tuning).
Examples: Tabnine; hypothetical examples: customer success or customer support applications, where someone could fine-tune a general model on proprietary data from Zendesk support tickets; in the legal field, a general model could be fine-tuned to write in the style of a specific law firm.
Costs: In the short term, this solution is expected to be significantly cheaper and faster than training a proprietary model. However, the costs of using a closed-source API are still relatively high, and at scale, these costs could burden a startup. Note that a startup can use a third-party model API with or without fine-tuning it, but companies that use the API as-is would not have a technological moat around generative AI. The other option, using an open-source model and fine-tuning it in-house, would probably be cheaper in regard to usage and training costs, but requires having a strong in-house team to assemble the model and fine-tune it. The general assumption today is that costs will decrease over time, as the models become more efficient.
What you need to believe:
A model that was fine-tuned can outperform a very large model in the long term.
There is such a thing as a “proprietary data set,” and startups can get a hold of it and maintain their data advantage for 5-10 years, until they establish other moats.
Risks: Under the “one model to rule them all” assumption, it is unclear how much a data moat is actually a moat. Even if a huge LLM needs more fine-tuning, it may be that it only needs a very small number of examples, and from there the model can extrapolate. Suppose the big model turns out to only need 10 examples; it sounds reasonable that a competitor could produce those 10 examples in many cases (customer support tickets, legal contracts, Python commands), thus negating the advantage of a proprietary data set.
Conclusion: While in many of our conversations, the notion of having a proprietary data set was perceived as a defensible moat, we’re skeptical that this will remain a moat over time if large LLMs are able to learn from very few training examples.
Harnessing LLMs in combination with other technology to solve hard problems
How this works: This moat does not derive directly from the model, but using LLM can unlock ways to solve other hard problems. James Currier of NFX described this as “using generative AI to give you an advantage over competition.” The value prop is not the AI itself, but the service delivered to the customer, which can be delivered more quickly and more cheaply using AI.
Examples: Mem is building a “self-organizing workspace” that uses AI to categorize a user’s notes, with the longer-term goal of being like a Google search for all your proprietary data; the value prop is the ability to look up anything you want to remember very quickly, and they use generative AI to improve their ability to provide useful outputs to a user. Tome is building a product that makes it easier to tell compelling stories in slides, which started out as a set of creation tools before they added a generative AI component to lower the friction to creation even more. In both cases, generative AI allows the companies to deliver a better service to the customer, but it is not the main value prop. (Both companies received investments from OpenAI, which means they got early access to GPT-4, an extra technological advantage in the short-term.)
Costs: Similar to applications that are built on top of a third-party’s model (#2).
What you need to believe: There is enough value provided by the other technology built by the company that another company cannot easily copy the solution just by using the same LLM.
Risks: Investors and startups should make sure the generative AI component was added for a reason, not just to generate buzz or hype.
Conclusion: This is a very strong way to build a moat, provided the technology you’re using in combination with generative AI is not easily replicable.
First-mover advantage based on human feedback.
How this works: This is the generative AI equivalent to a network effect: as a company attracts more users to use its generative AI product, it can build infrastructure to collect and label data on how users interact with the product. This data can be used to continuously train and improve the model to satisfy user needs. For example, as OpenAI collects feedback from people using ChatGPT, it can further refine the model, giving it an advantage in achieving “alignment” (models that produce outputs aligned with what humans intended them to produce). OpenAI published a blog describing how GPT3 significantly improved at following a user’s intention, being more truthful, and being less toxic using this method, which is known as “reinforcement learning from human feedback” (RLHF).
Examples: ChatGPT
Costs: Running the infrastructure and automatically “feeding” the data back to the model requires an in-house data team, which can lead to high costs.
What you need to believe: The way users interact with the model is the “real” unique data set that can’t be replicated (unlike an “external” data set of examples that are used for training the models to perform certain tasks).
Risks: The process of “alignment” allows for tweaking the product, but may not have a significant impact on the overall experience of the users.
Conclusion: At this time, we believe this is the deepest moat a company can build. The first company in each market to capture users’ data on what the users “really” want from the model, and use it to better align its model, will have a significant moat. Interestingly, when defensibility came up in most of our interviews, many people opined that AI copywriting tool Jasper lacks defensibility because it’s just a wrapper around OpenAI’s API. That said, we think Jasper may end up building a moat by virtue of its first-mover advantage, not only because it may becoming embedded in organizations, but because it potentially could capture so much of its users’ feedback.
Parting thoughts
We’re still in the very early days of generative AI, and it is unclear what the end market will look like. Will there be huge “LLMs as a service” from cloud providers, will each company have a niche model of its own, or is the whole market overhyped, such that the number of applications will be smaller than expected? As large incumbents like Microsoft and Google rush to enter the market, where will startups be best positioned to win? Either way, one thing that can help companies succeed is having a flexible infrastructure and a quick method to assess new models as they come out. This way, companies can adopt and drop models very frequently, based on how they complement their products. We believe this is a must-have approach at this time.
All the moats described above are capped by scarce talent and by cost structure. One of our takeaways is that at this point in time, the way to build defensibility is tightly connected with cost structure; the cost structure itself can give rise to moats, as the costs of using a model via an API will burden companies that already reached scale, and we will discuss this in a future post.
Special thanks to Amanda Kelly and Brian Tuan for comments on an earlier draft of this post.
 |
|